![]()
![]()
| Related Topics: | ||
Description: In the Fleet data type, the analysis stacks the failure times of each system in the data set into a cumulative timeline, and then converts it to grouped data based on the intervals you specify. Depending on the model you are working with, this function allows you to manually build a table that shows the number of failures in each interval (Crow-AMSAA model) or the number of distinct modes in each interval (Crow Extended model).
Syntax: CUMTIMELINE (Data_Src, Row, Column)
Data_Src is the source data sheet from which the information is taken.
Depending on the model you are working with, the Row and Column parameters will return the following information:
For the Crow-AMSAA model:
Row corresponds to the order of the intervals (i.e., row 1 = 1st interval, row 2 = 2nd interval, etc.).
Column is an index value (from 1 to 3) that returns the following information:
1 = returns the number that is specified in Row.
2 = returns the number of failures that occurred in the interval. The failure numbers are non-cumulative (where each row shows the number of failures that occurred in that interval only).
3 = returns the time at which the interval ended. The times are cumulative (where each row shows the total amount of operating time accumulated by the end of each interval).
For the Crow Extended model:
Row corresponds to the order in which the unique modes appeared in a specified interval (i.e., row 1 = 1st unique mode that occurred, row 2 = 2nd unique mode that occurred, etc.).
Column is an index value (from 1 to 5) that returns the following information:
1 = returns the number that is specified in Row.
2 = returns the number of distinct modes in the interval.
3 = returns the time at which the interval ended.
4 = returns the mode classification
5 = returns the failure mode.
Remarks:
The Data_Src can be one of the following values:
If using a default data source, it must be either 1, 2, 3 or 4, as selected from the Data Source Index drop-down list.
It can take a data sheet name (e.g., "Folio1!Data 1").
It can take a variable name defined in the Defined Names window (e.g., datasource).
The Row and Column values must be greater than 0.
Examples:
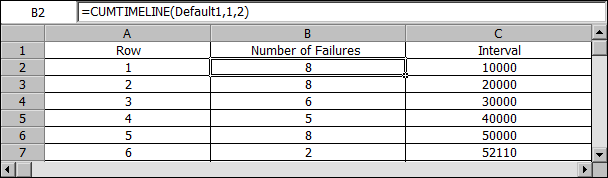
The following table is for a particular data set analyzed with the Crow-AMSAA (NHPP) model. In the first configuration (row 1), there were 8 failures in the first 10,000 hours of operation. In the second configuration (row 2) there were 8 more failures in the next 10,000 hours of operation ( for a total of 20,000 hours). The rest of the data can be read in a similar manner.
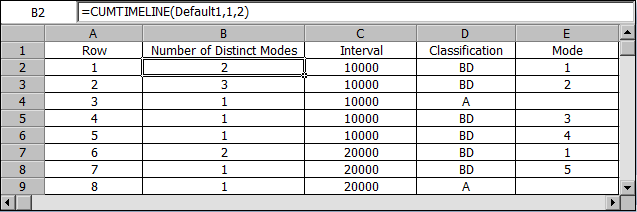
The next example is for a data set analyzed with the Crow Extended model. It shows the number of distinct modes in each of the intervals. In the first configuration (rows 1 to 5) , there were 5 distinct modes in the first 10,000 hours of operation: row 1 shows that there were two BD1 modes, row 2 shows that there were three BD2 modes, row 3 shows that there was one A mode and row 5 shows that there was 1 BD4 mode.
Note that the values depend on the source data set.
© 1992-2015. ReliaSoft Corporation. ALL RIGHTS RESERVED.